부제: df.replace("-", np.NAN, inplace=True)
안녕하세요, 아과입니다.

오늘은 데이터 프레임(Dataframe)에서 특정 값을 바꾸거나 Null 처리하는 방법을 알아보도록 하겠습니다.
오늘의 글은 다음순서로 진행됩니다.
- example.xls 읽어오기
- 특정 문자열을 특정 값 혹은 Null 값으로 바꾸기 : df.replace("-", np.NAN, inplace=True)
- NaN으로 변경된 것을 최종적으로 None로 바꾸기 : df.replace({np.nan: None}, inplace=True)
- 변경된 값 확인하기 : df.iloc[1].tolist()
예제파일은 다음과 같습니다.
파이썬에서 pandas로 엑셀 파일을 읽어오면 수치로 들어갈 부분에 데이터가 없을 경우 "-" 값으로 보내줍니다.
이것을 DB에 그대로 넣으면 다음과 같은 오류가 뜹니다.

pyodbc.ProgrammingError: ('42000', '[42000] [Microsoft][ODBC SQL Server Driver][SQL Server]데이터 형식 nvarchar을(를) float(으)로 변환하는 중 오류가 발생했습니다. (8114) (SQLExecDirectW)')
그럴 때 유용하게 쓰기 위해 Dataframe에서 특정 값을 일괄 변환해야 할 때 쓰는 함수를 알아보도록 하겠습니다.
1. example.xls 읽어오기
이번에도 엑셀파일 읽어오기부터 시작하겠습니다.
import pandas as pd
df = pd.read_excel("example.xlsx", engine='openpyxl')
print(df)example.xlsx파일의 값들을 데이터 프레임(dataframe)인 df로 담아왔습니다.
이 엑셀은 수익률이 들어갈 곳에 데이터가 없으면 "-"로 보내줍니다.
이것을 그대로 DB에 넣으면 float으로 들어가야 할 곳에 문자열인 "-"가 들어오므로 오류를 발생하게 됩니다.
그러기 위해서는 "-"를 Null 값으로 바꿔줘야 합니다.
2. 특정 문자열을 특정 값 혹은 Null 값으로 바꾸기 : df.replace("-", np.NAN, inplace=True)
일단 특정값으로 바꾸는 것은 편합니다.
"-"로 들어온 값을 0으로 바꾸기 위해서는 아래처럼 하면 됩니다.
df.replace("-", 0, inplace=True)
그런데 수익률 같은 경우 데이터가 없으면 0으로 할 것이 아니라 Null 값으로 줘야 합니다.
즉, 다음과 같이 처리하는 것이 더 좋습니다.
df.replace("-", np.NAN, inplace=True)
수익률 같은 정보는 없음을 나타낼 때는 Null로 나타내야 합니다
-아과노트-
3.NaN으로 변경된 것을 최종적으로 None로 바꾸기 : df.replace({np.nan: None})
하지만 여기서 끝이 아닙니다. DB에 넣을 때 Numpy의 NaN 값은 DB에 알아서 NULL로 넣어주면 좋겠지만...
그렇게 되지 않습니다.
그럴 때는 또 Numpy의 NaN 값을 최종적으로 None의 값으로 바꿔야 DB에 NULL로 입력이 됩니다.
이것을 바꾸는 명령어는 다음과 같습니다.
df.replace({np.nan: None}, inplace=True)
df.replace({np.nan: None}, inplace=True)여기까지 가야 최종적으로 None로 만들어집니다.
4. 변경된 값 확인하기 : df.iloc[1].tolist()
변경된 값을 확인하기 위해 빠르게 다음과 같이 입력합니다
df.iloc[1].tolist()
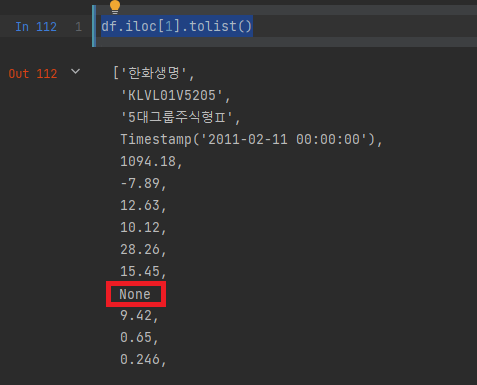
그러면 기존에 "-"로 들어왔던 값이 nan으로 변경된 것을 볼 수 있습니다.
오늘도 고생하셨습니다.